 ++++
++++Notebook converted from Jupyter for blog publishing.
00-Sup-Learning-Capstone-Tree-Methods
Supervised Learning Capstone Project - Tree Methods Focus
Make sure to review the introduction video to understand the 3 ways of approaching this project exercise!
Ways to approach the project:
- Open a new notebook, read in the data, and then analyze and visualize whatever you want, then create a predictive model.
- Use this notebook as a general guide, completing the tasks in bold shown below.
- Skip to the solutions notebook and video, and treat project at a more relaxing code along walkthrough lecture series.
GOAL: Create a model to predict whether or not a customer will Churn .
Complete the Tasks in Bold Below!
Part 0: Imports and Read in the Data
TASK: Run the filled out cells below to import libraries and read in your data. The data file is "Telco-Customer-Churn.csv"
# RUN THESE CELLS TO START THE PROJECT!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsdf = pd.read_csv('../DATA/Telco-Customer-Churn.csv')df.head()customerID
gender
SeniorCitizen
Partner
DependentsPart 1: Quick Data Check
TASK: Confirm quickly with .info() methods the datatypes and non-null values in your dataframe.
# CODE HERETASK: Get a quick statistical summary of the numeric columns with .describe() , you should notice that many columns are categorical, meaning you will eventually need to convert them to dummy variables.
# CODE HEREPart 2: Exploratory Data Analysis
General Feature Exploration
TASK: Confirm that there are no NaN cells by displaying NaN values per feature column.
# CODE HERETASK:Display the balance of the class labels (Churn) with a Count Plot.
# CODE HERE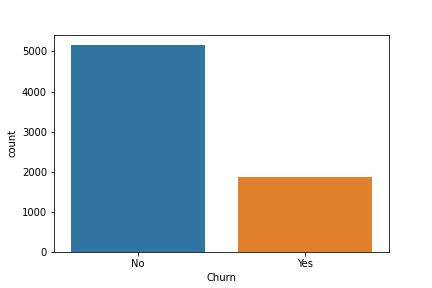
TASK: Explore the distrbution of TotalCharges between Churn categories with a Box Plot or Violin Plot.
# CODE HERE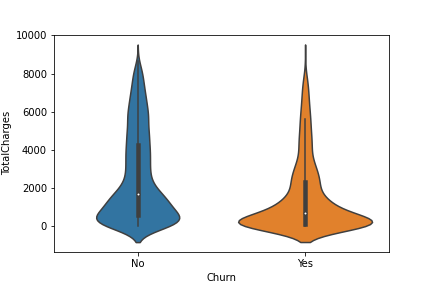
TASK: Create a boxplot showing the distribution of TotalCharges per Contract type, also add in a hue coloring based on the Churn class.
#CODE HERE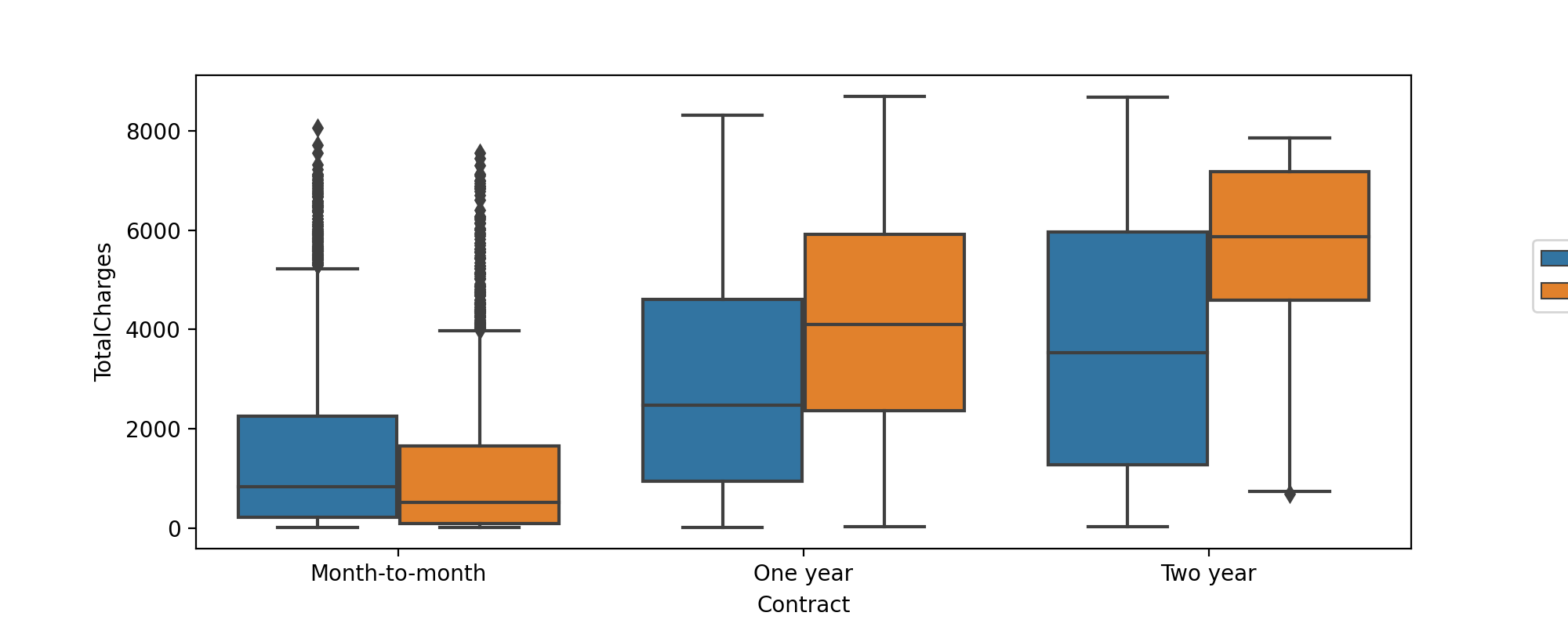
TASK: Create a bar plot showing the correlation of the following features to the class label. Keep in mind, for the categorical features, you will need to convert them into dummy variables first, as you can only calculate correlation for numeric features.
['gender', 'SeniorCitizen', 'Partner', 'Dependents','PhoneService', 'MultipleLines', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'InternetService', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod']
Note, we specifically listed only the features above, you should not check the correlation for every feature, as some features have too many unique instances for such an analysis, such as customerID
#CODE HERE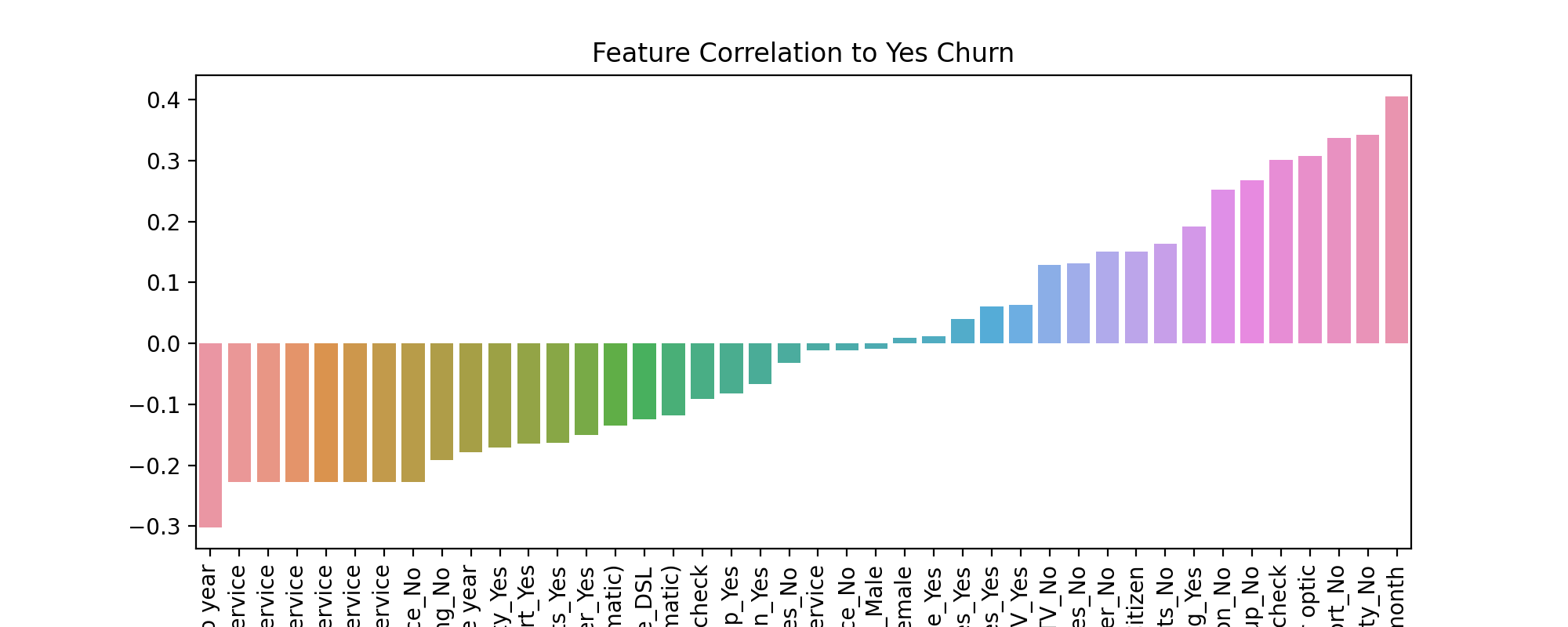
Part 3: Churn Analysis
This section focuses on segementing customers based on their tenure, creating "cohorts", allowing us to examine differences between customer cohort segments.
TASK: What are the 3 contract types available?
# CODE HERETASK: Create a histogram displaying the distribution of 'tenure' column, which is the amount of months a customer was or has been on a customer.
#CODE HERE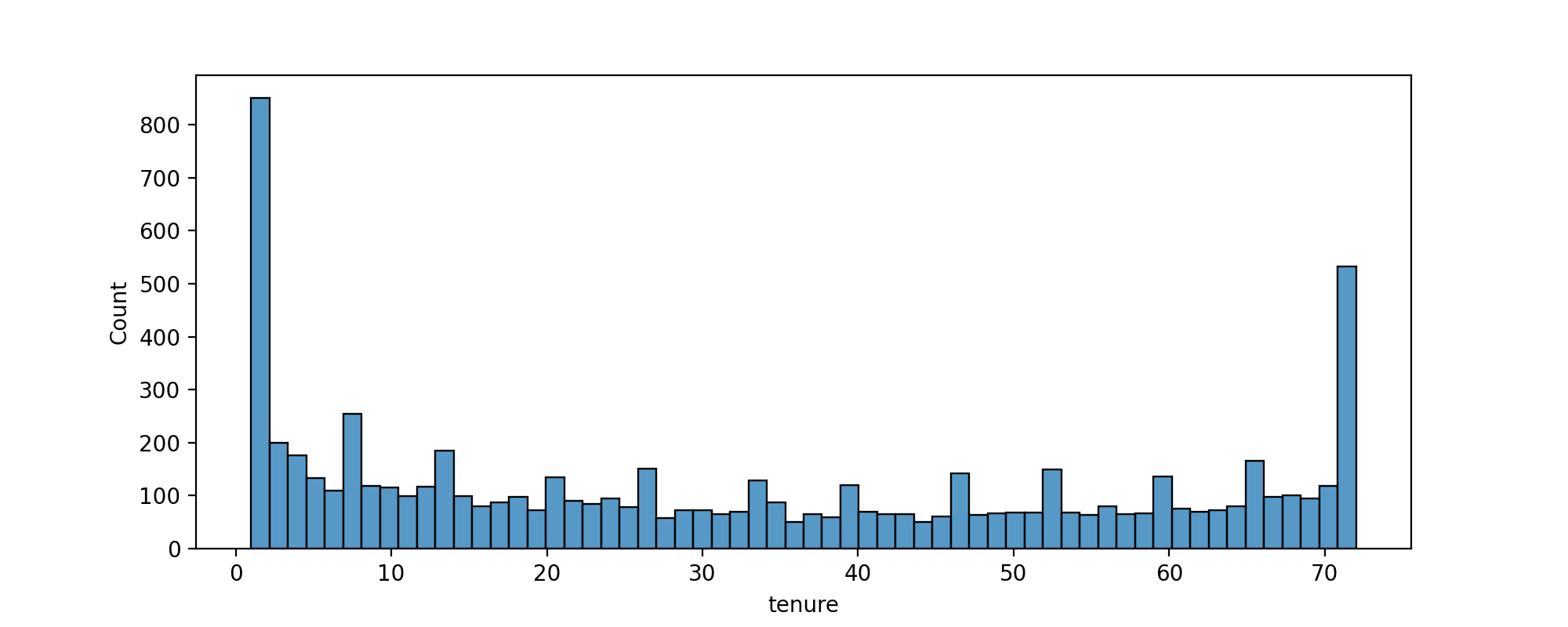
TASK: Now use the seaborn documentation as a guide to create histograms separated by two additional features, Churn and Contract.
#CODE HERE
TASK: Display a scatter plot of Total Charges versus Monthly Charges, and color hue by Churn.
#CODE HERE
Creating Cohorts based on Tenure
Let's begin by treating each unique tenure length, 1 month, 2 month, 3 month...N months as its own cohort.
TASK: Treating each unique tenure group as a cohort, calculate the Churn rate (percentage that had Yes Churn) per cohort. For example, the cohort that has had a tenure of 1 month should have a Churn rate of 61.99%. You should have cohorts 1-72 months with a general trend of the longer the tenure of the cohort, the less of a churn rate. This makes sense as you are less likely to stop service the longer you've had it.
#CODE HERETASK: Now that you have Churn Rate per tenure group 1-72 months, create a plot showing churn rate per months of tenure.
#CODE HERE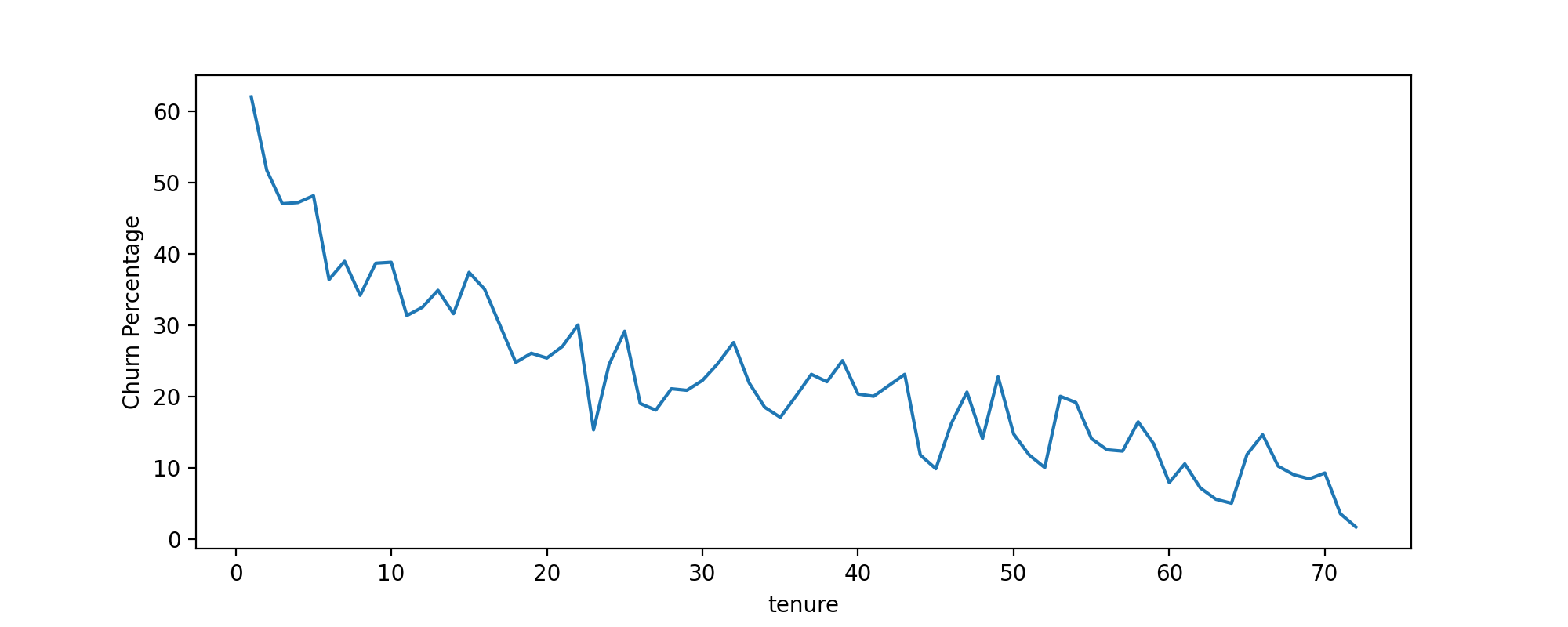
Broader Cohort Groups
TASK: Based on the tenure column values, create a new column called Tenure Cohort that creates 4 separate categories:
- '0-12 Months'
- '12-24 Months'
- '24-48 Months'
- 'Over 48 Months'
# CODE HERETASK: Create a scatterplot of Total Charges versus Monthly Charts,colored by Tenure Cohort defined in the previous task.
#CODE HERE
TASK: Create a count plot showing the churn count per cohort.
# CODE HERE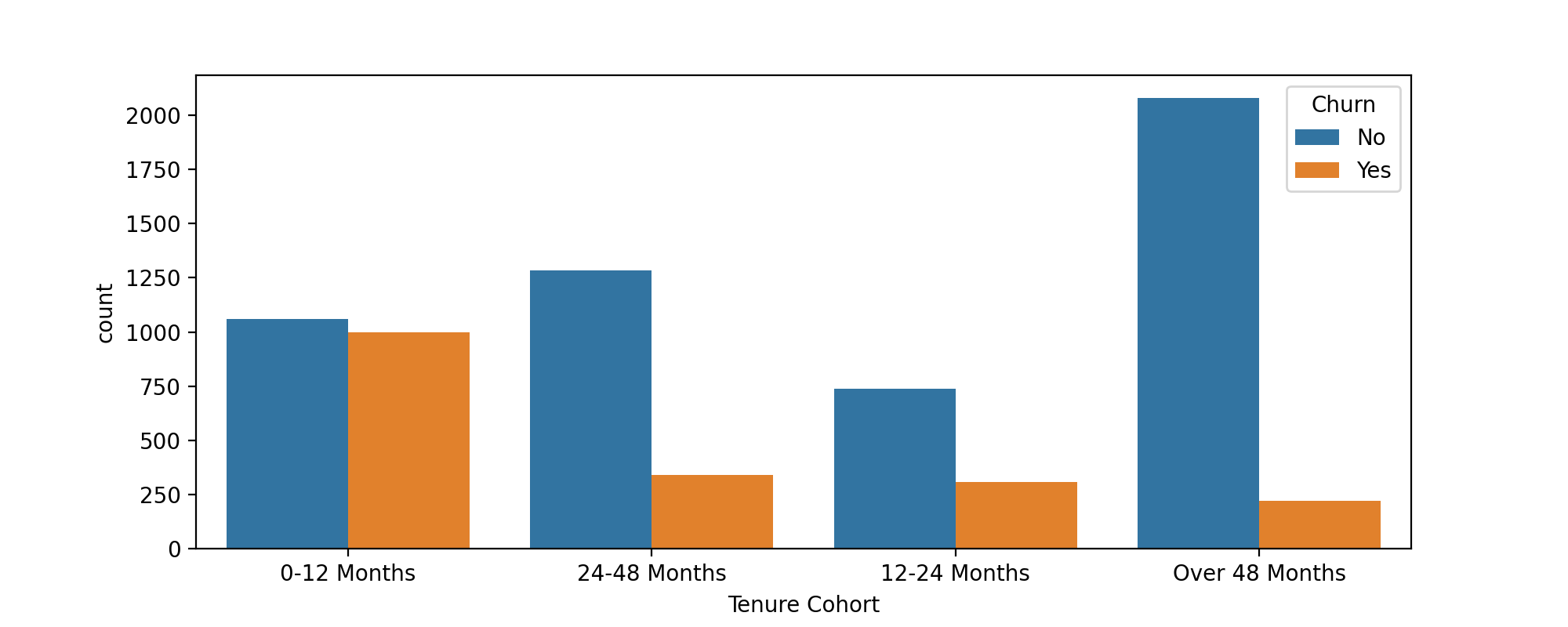
TASK: Create a grid of Count Plots showing counts per Tenure Cohort, separated out by contract type and colored by the Churn hue.
#CODE HERE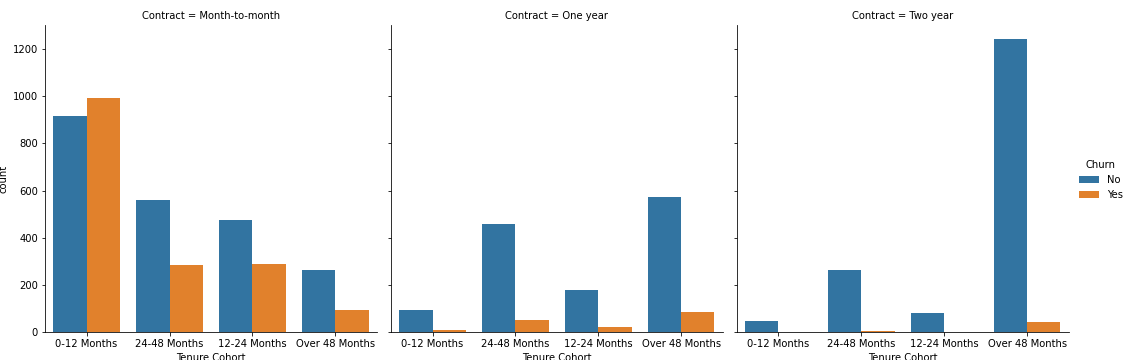
Part 4: Predictive Modeling
Let's explore 4 different tree based methods: A Single Decision Tree, Random Forest, AdaBoost, Gradient Boosting. Feel free to add any other supervised learning models to your comparisons!
Single Decision Tree
TASK : Separate out the data into X features and Y label. Create dummy variables where necessary and note which features are not useful and should be dropped.
#CODE HERETASK: Perform a train test split, holding out 10% of the data for testing. We'll use a random_state of 101 in the solutions notebook/video.
#CODE HERETASK: Decision Tree Perfomance. Complete the following tasks:
- Train a single decision tree model (feel free to grid search for optimal hyperparameters).
- Evaluate performance metrics from decision tree, including classification report and plotting a confusion matrix.
- Calculate feature importances from the decision tree.
- OPTIONAL: Plot your tree, note, the tree could be huge depending on your pruning, so it may crash your notebook if you display it with plot_tree.
Random Forest
TASK: Create a Random Forest model and create a classification report and confusion matrix from its predicted results on the test set.
#CODE HEREBoosted Trees
TASK: Use AdaBoost or Gradient Boosting to create a model and report back the classification report and plot a confusion matrix for its predicted results
#CODE HERETASK: Analyze your results, which model performed best for you?
# With base models, we got best performance from an AdaBoostClassifier, but note, we didn't do any gridsearching AND most models performed about the same on the data set.