 ++++
++++Unlock the reasoning power of LLMs. Learn how breaking down problems into intermediate steps can solve complex arithmetic, commonsense, and symbolic tasks.
Chain-of-Thought Prompting 🧠
This content is adapted from Prompting Guide: Chain-of-Thought Prompting. It has been curated and organized for educational purposes on this portfolio. No copyright infringement is intended.
Chain-of-Thought (CoT) Prompting
Introduced in Wei et al. (2022) (opens in a new tab), chain-of-thought (CoT) prompting You can combine it with few-shot prompting to get better results on more complex tasks that require reasoning before responding.
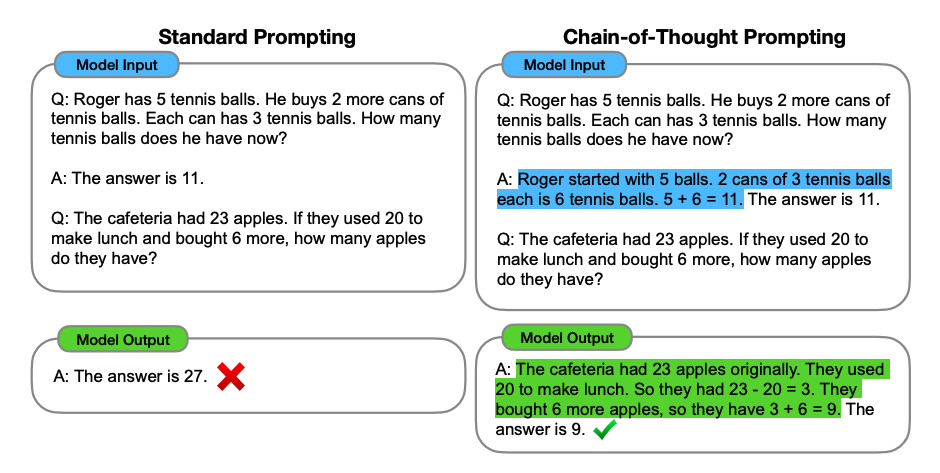
CoT in Action: Reasoning via Examples
In the following example, we provide the model with several demonstrations of how to solve the problem, rather than just the final answer.
Prompt (4-Shot CoT):
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.Wow! We can see a perfect result when we provided the reasoning step. In fact, providing even fewer examples (1-shot) is often enough for modern models to pick up the pattern.
Zero-Shot CoT Prompting
Research by Kojima et al. (2022) (opens in a new tab) discovered that you can trigger CoT reasoning without manual examples by adding the phrase "Let's think step by step" to the original prompt.

"Market & Apples" Comparison
Prompt (Standard):
"I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?"
Output: 11 apples (Incorrect)
Prompt (Zero-Shot CoT):
"I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with? Let's think step by step."
Output:
First, you started with 10 apples. You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left. Then you bought 5 more apples, so now you had 11 apples. Finally, you ate 1 apple, so you would remain with 10 apples. (Correct)
Automatic Chain-of-Thought (Auto-CoT)
When applying CoT with demonstrations, researchers noticed that hand-crafting diverse examples is often a bottleneck and could lead to suboptimal solutions. Zhang et al. (2022) (opens in a new tab) proposed Auto-CoT to eliminate manual effort by leveraging LLMs to generate reasoning chains for demonstrations.
Auto-CoT consists of two main stages:
- Question Clustering: Partitioning the dataset questions into several distinct clusters.
- Demonstration Sampling: Selecting a representative question from each cluster and generating its reasoning chain via Zero-Shot CoT with simple heuristics.

The simple heuristics, such as question length (e.g., 60 tokens) and number of rationale steps (e.g., 5 steps), encourage the model to use simple and accurate demonstrations.
[!TIP] The source code for Auto-CoT is available on GitHub (opens in a new tab).
Why CoT Matters
CoT is an emergent ability. It typically only appears in models of a certain scale (e.g., ~175B parameters or larger). For smaller models, adding intermediate steps can actually decrease performance by introducing more tokens for the model to hallucinate or drift away from the core task.