 ++++
++++Notebook converted from Jupyter for blog publishing.
00-Cross-Validation
Introduction to Cross Validation
In this lecture series we will do a much deeper dive into various methods of cross-validation. As well as a discussion on the general philosphy behind cross validation. A nice official documentation guide can be found here: https://scikit-learn.org/stable/modules/cross_validation.html (opens in a new tab)
Imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsC:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tools\_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tmData Example
df = pd.read_csv("../DATA/Advertising.csv")df.head()TV
radio
newspaper
sales
0Train | Test Split Procedure
- Clean and adjust data as necessary for X and y
- Split Data in Train/Test for both X and y
- Fit/Train Scaler on Training X Data
- Scale X Test Data
- Create Model
- Fit/Train Model on X Train Data
- Evaluate Model on X Test Data (by creating predictions and comparing to Y_test)
- Adjust Parameters as Necessary and repeat steps 5 and 6
## CREATE X and y
X = df.drop('sales',axis=1)
y = df['sales']
# TRAIN TEST SPLIT
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=101)
# SCALE DATA
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Create Model
from sklearn.linear_model import Ridge# Poor Alpha Choice on purpose!
model = Ridge(alpha=100)model.fit(X_train,y_train)Ridge(alpha=100, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)y_pred = model.predict(X_test)Evaluation
from sklearn.metrics import mean_squared_errormean_squared_error(y_test,y_pred)7.34177578903413Adjust Parameters and Re-evaluate
model = Ridge(alpha=1)model.fit(X_train,y_train)Ridge(alpha=1, copy_X=True, fit_intercept=True, max_iter=None, normalize=False,
random_state=None, solver='auto', tol=0.001)y_pred = model.predict(X_test)Another Evaluation
mean_squared_error(y_test,y_pred)2.319021579428752Much better! We could repeat this until satisfied with performance metrics. (We previously showed RidgeCV can do this for us, but the purpose of this lecture is to generalize the CV process for any model).
Train | Validation | Test Split Procedure
This is often also called a "hold-out" set, since you should not adjust parameters based on the final test set, but instead use it only for reporting final expected performance.
- Clean and adjust data as necessary for X and y
- Split Data in Train/Validation/Test for both X and y
- Fit/Train Scaler on Training X Data
- Scale X Eval Data
- Create Model
- Fit/Train Model on X Train Data
- Evaluate Model on X Evaluation Data (by creating predictions and comparing to Y_eval)
- Adjust Parameters as Necessary and repeat steps 5 and 6
- Get final metrics on Test set (not allowed to go back and adjust after this!)
## CREATE X and y
X = df.drop('sales',axis=1)
y = df['sales']######################################################################
#### SPLIT TWICE! Here we create TRAIN | VALIDATION | TEST #########
####################################################################
from sklearn.model_selection import train_test_split
# 70% of data is training data, set aside other 30%
X_train, X_OTHER, y_train, y_OTHER = train_test_split(X, y, test_size=0.3, random_state=101)
# Remaining 30% is split into evaluation and test sets
# Each is 15% of the original data size
X_eval, X_test, y_eval, y_test = train_test_split(X_OTHER, y_OTHER, test_size=0.5, random_state=101)# SCALE DATA
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_eval = scaler.transform(X_eval)
X_test = scaler.transform(X_test)Create Model
from sklearn.linear_model import Ridge# Poor Alpha Choice on purpose!
model = Ridge(alpha=100)model.fit(X_train,y_train)Ridge(alpha=100, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)y_eval_pred = model.predict(X_eval)Evaluation
from sklearn.metrics import mean_squared_errormean_squared_error(y_eval,y_eval_pred)7.320101458823871Adjust Parameters and Re-evaluate
model = Ridge(alpha=1)model.fit(X_train,y_train)Ridge(alpha=1, copy_X=True, fit_intercept=True, max_iter=None, normalize=False,
random_state=None, solver='auto', tol=0.001)y_eval_pred = model.predict(X_eval)Another Evaluation
mean_squared_error(y_eval,y_eval_pred)2.383783075056986Final Evaluation (Can no longer edit parameters after this!)
y_final_test_pred = model.predict(X_test)mean_squared_error(y_test,y_final_test_pred)2.254260083800517Cross Validation with cross_val_score
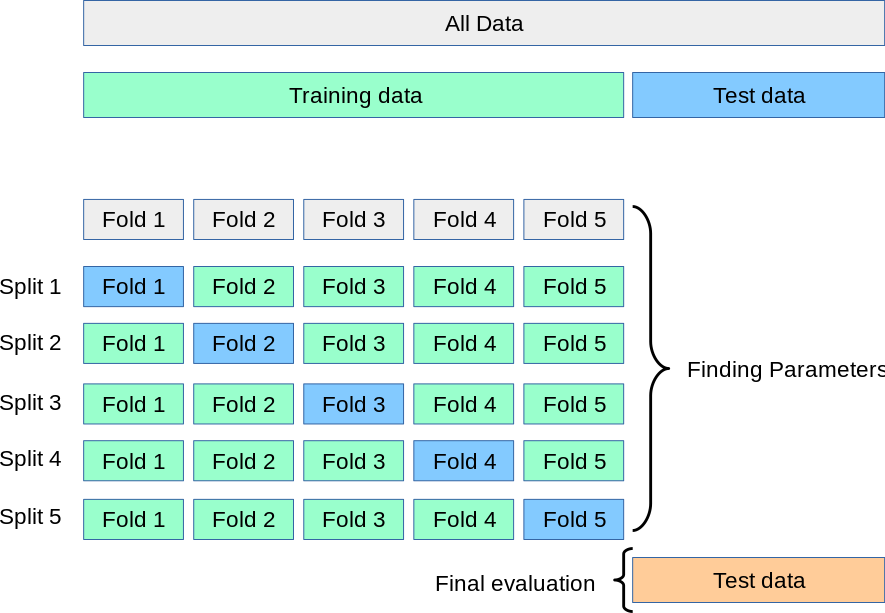
## CREATE X and y
X = df.drop('sales',axis=1)
y = df['sales']
# TRAIN TEST SPLIT
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=101)
# SCALE DATA
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)model = Ridge(alpha=100)from sklearn.model_selection import cross_val_score# SCORING OPTIONS:
# https://scikit-learn.org/stable/modules/model_evaluation.html
scores = cross_val_score(model,X_train,y_train,
scoring='neg_mean_squared_error',cv=5)scoresarray([ -9.32552967, -4.9449624 , -11.39665242, -7.0242106 ,
-8.38562723])# Average of the MSE scores (we set back to positive)
abs(scores.mean())8.215396464543607Adjust model based on metrics
model = Ridge(alpha=1)# SCORING OPTIONS:
# https://scikit-learn.org/stable/modules/model_evaluation.html
scores = cross_val_score(model,X_train,y_train,
scoring='neg_mean_squared_error',cv=5)# Average of the MSE scores (we set back to positive)
abs(scores.mean())3.344839296530695Final Evaluation (Can no longer edit parameters after this!)
# Need to fit the model first!
model.fit(X_train,y_train)Ridge(alpha=1, copy_X=True, fit_intercept=True, max_iter=None, normalize=False,
random_state=None, solver='auto', tol=0.001)y_final_test_pred = model.predict(X_test)mean_squared_error(y_test,y_final_test_pred)2.319021579428752Cross Validation with cross_validate
The cross_validate function differs from cross_val_score in two ways:
It allows specifying multiple metrics for evaluation.
It returns a dict containing fit-times, score-times (and optionally training scores as well as fitted estimators) in addition to the test score.
For single metric evaluation, where the scoring parameter is a string, callable or None, the keys will be:
- ['test_score', 'fit_time', 'score_time']
And for multiple metric evaluation, the return value is a dict with the following keys:
['test_<scorer1_name>', 'test_<scorer2_name>', 'test_<scorer...>', 'fit_time', 'score_time']
return_train_score is set to False by default to save computation time. To evaluate the scores on the training set as well you need to be set to True.
## CREATE X and y
X = df.drop('sales',axis=1)
y = df['sales']
# TRAIN TEST SPLIT
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=101)
# SCALE DATA
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)model = Ridge(alpha=100)from sklearn.model_selection import cross_validate# SCORING OPTIONS:
# https://scikit-learn.org/stable/modules/model_evaluation.html
scores = cross_validate(model,X_train,y_train,
scoring=['neg_mean_absolute_error','neg_mean_squared_error','max_error'],cv=5)scores{'fit_time': array([0.00102687, 0.00088882, 0.00099993, 0.00099945, 0. ]),
'score_time': array([0.00108409, 0. , 0. , 0.00064516, 0.00086308]),
'test_neg_mean_absolute_error': array([-2.31243044, -1.74653361, -2.56211701, -2.01873159, -2.27951906]),
'test_neg_mean_squared_error': array([ -9.32552967, -4.9449624 , -11.39665242, -7.0242106 ,
-8.38562723]),pd.DataFrame(scores)fit_time
score_time
test_neg_mean_absolute_error
test_neg_mean_squared_error
test_max_errorpd.DataFrame(scores).mean()fit_time 0.000783
score_time 0.000518
test_neg_mean_absolute_error -2.183866
test_neg_mean_squared_error -8.215396
test_max_error -7.350715Adjust model based on metrics
model = Ridge(alpha=1)# SCORING OPTIONS:
# https://scikit-learn.org/stable/modules/model_evaluation.html
scores = cross_validate(model,X_train,y_train,
scoring=['neg_mean_absolute_error','neg_mean_squared_error','max_error'],cv=5)pd.DataFrame(scores).mean()fit_time 0.000901
score_time 0.000200
test_neg_mean_absolute_error -1.319685
test_neg_mean_squared_error -3.344839
test_max_error -5.161145Final Evaluation (Can no longer edit parameters after this!)
# Need to fit the model first!
model.fit(X_train,y_train)Ridge(alpha=1, copy_X=True, fit_intercept=True, max_iter=None, normalize=False,
random_state=None, solver='auto', tol=0.001)y_final_test_pred = model.predict(X_test)mean_squared_error(y_test,y_final_test_pred)2.319021579428752