 ++++
++++Notebook converted from Jupyter for blog publishing.
08-Seaborn-Exercise-Solutions
Seaborn Exercises - Solutions
Imports
Run the cell below to import the libraries
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as pltThe Data
DATA SOURCE: https://www.kaggle.com/rikdifos/credit-card-approval-prediction (opens in a new tab)
Data Information:
Credit score cards are a common risk control method in the financial industry. It uses personal information and data submitted by credit card applicants to predict the probability of future defaults and credit card borrowings. The bank is able to decide whether to issue a credit card to the applicant. Credit scores can objectively quantify the magnitude of risk.
Feature Information:
<table> <thead> <tr> <th>application_record.csv</th> <th></th> <th></th> </tr> </thead> <tbody> <tr> <td>Feature name</td> <td>Explanation</td> <td>Remarks</td> </tr> <tr> <td><code>ID</code></td> <td>Client number</td> <td></td> </tr> <tr> <td><code>CODE_GENDER</code></td> <td>Gender</td> <td></td> </tr> <tr> <td><code>FLAG_OWN_CAR</code></td> <td>Is there a car</td> <td></td> </tr> <tr> <td><code>FLAG_OWN_REALTY</code></td> <td>Is there a property</td> <td></td> </tr> <tr> <td><code>CNT_CHILDREN</code></td> <td>Number of children</td> <td></td> </tr> <tr> <td><code>AMT_INCOME_TOTAL</code></td> <td>Annual income</td> <td></td> </tr> <tr> <td><code>NAME_INCOME_TYPE</code></td> <td>Income category</td> <td></td> </tr> <tr> <td><code>NAME_EDUCATION_TYPE</code></td> <td>Education level</td> <td></td> </tr> <tr> <td><code>NAME_FAMILY_STATUS</code></td> <td>Marital status</td> <td></td> </tr> <tr> <td><code>NAME_HOUSING_TYPE</code></td> <td>Way of living</td> <td></td> </tr> <tr> <td><code>DAYS_BIRTH</code></td> <td>Birthday</td> <td>Count backwards from current day (0), -1 means yesterday</td> </tr> <tr> <td><code>DAYS_EMPLOYED</code></td> <td>Start date of employment</td> <td>Count backwards from current day(0). If positive, it means the person currently unemployed.</td> </tr> <tr> <td><code>FLAG_MOBIL</code></td> <td>Is there a mobile phone</td> <td></td> </tr> <tr> <td><code>FLAG_WORK_PHONE</code></td> <td>Is there a work phone</td> <td></td> </tr> <tr> <td><code>FLAG_PHONE</code></td> <td>Is there a phone</td> <td></td> </tr> <tr> <td><code>FLAG_EMAIL</code></td> <td>Is there an email</td> <td></td> </tr> <tr> <td><code>OCCUPATION_TYPE</code></td> <td>Occupation</td> <td></td> </tr> <tr> <td><code>CNT_FAM_MEMBERS</code></td> <td>Family size</td> <td></td> </tr> </tbody> </table>
df = pd.read_csv('application_record.csv')df.head()ID
CODE_GENDER
FLAG_OWN_CAR
FLAG_OWN_REALTY
CNT_CHILDRENdf.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 438557 entries, 0 to 438556
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- ----- TASKS
Recreate the plots shown in the markdown image cells. Each plot also contains a brief description of what it is trying to convey. Note, these are meant to be quite challenging. Start by first replicating the most basic form of the plot, then attempt to adjust its styling and parameters to match the given image.
In general do not worry about coloring,styling, or sizing matching up exactly. Instead focus on the content of the plot itself. Our goal is not to test you on recognizing figsize=(10,8) , its to test your understanding of being able to see a requested plot, and reproducing it.
NOTE: You may need to perform extra calculations on the pandas dataframe before calling seaborn to create the plot.
TASK: Recreate the Scatter Plot shown below
The scatterplot attempts to show the relationship between the days employed versus the age of the person (DAYS_BIRTH) for people who were not unemployed. Note, to reproduce this chart you must remove unemployed people from the dataset first. Also note the sign of the axis, they are both transformed to be positive. Finally, feel free to adjust the alpha and linewidth parameters in the scatterplot since there are so many points stacked on top of each other.
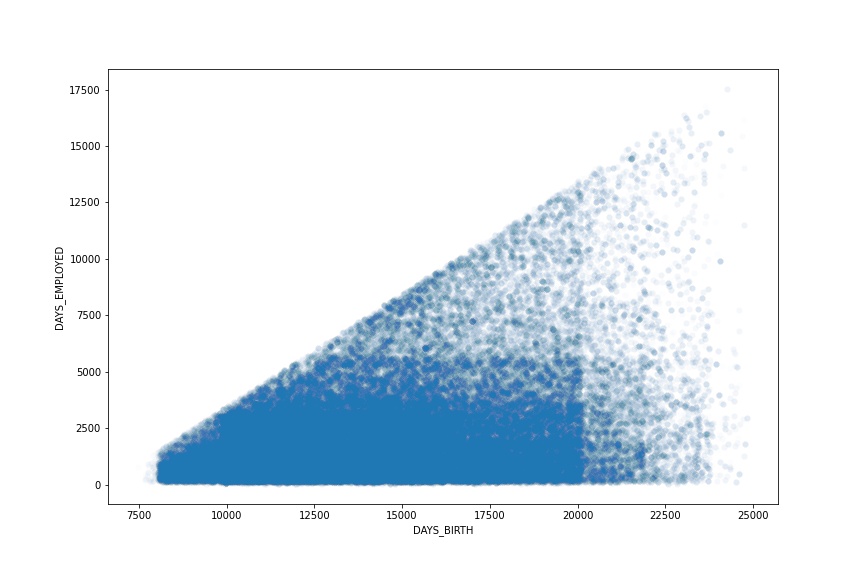
# CODE HERE TO RECREATE THE PLOT SHOWN ABOVEimport warningswarnings.simplefilter('ignore')plt.figure(figsize=(12,8))
# REMOVE UNEMPLOYED PEOPLE
employed = df[df['DAYS_EMPLOYED']<0]
# MAKE BOTH POSITIVE
employed['DAYS_EMPLOYED'] = -1*employed['DAYS_EMPLOYED']
employed['DAYS_BIRTH'] = -1*employed['DAYS_BIRTH']
# With so many points, alpha is tiny, might be an indicated that a
# scatterplot may not be the right choice!
sns.scatterplot(y='DAYS_EMPLOYED',x='DAYS_BIRTH',data=employed,
alpha=0.01,linewidth=0)
plt.savefig('task_one.jpg')
TASK: Recreate the Distribution Plot shown below:
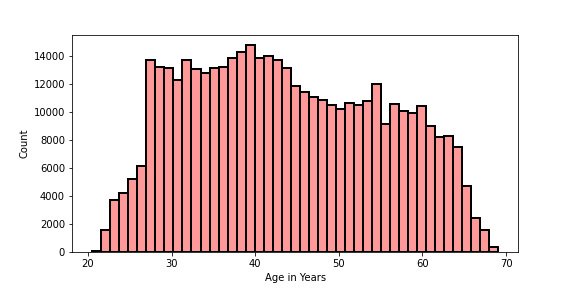
Note, you will need to figure out how to calculate "Age in Years" from one of the columns in the DF. Think carefully about this. Don't worry too much if you are unable to replicate the styling exactly.
# CODE HERE TO RECREATE THE PLOT SHOWN ABOVEplt.figure(figsize=(8,4))
df['YEARS'] = -1*df['DAYS_BIRTH']/365
sns.histplot(data=df,x='YEARS',linewidth=2,edgecolor='black',
color='red',bins=45,alpha=0.4)
plt.xlabel("Age in Years")
plt.savefig('DistPlot_solution.png')
TASK: Recreate the Categorical Plot shown below:
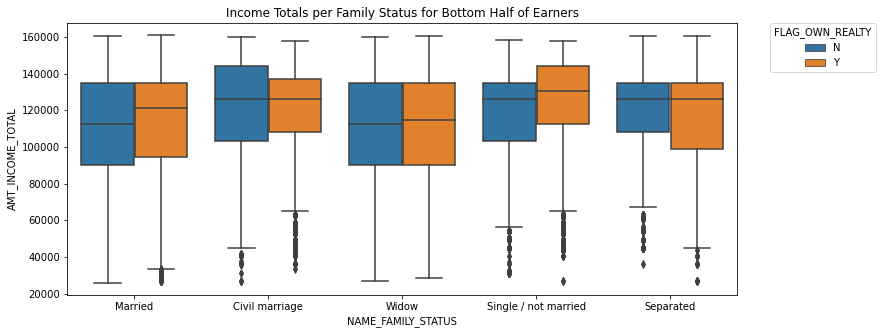
This plot shows information only for the bottom half of income earners in the data set. It shows the boxplots for each category of NAME_FAMILY_STATUS column for displaying their distribution of their total income. The hue is the "FLAG_OWN_REALTY" column. Note: You will need to adjust or only take part of the dataframe before recreating this plot.
# CODE HEREplt.figure(figsize=(12,5))
bottom_half_income = df.nsmallest(n=int(0.5*len(df)),columns='AMT_INCOME_TOTAL')
sns.boxplot(x='NAME_FAMILY_STATUS',y='AMT_INCOME_TOTAL',data=bottom_half_income,hue='FLAG_OWN_REALTY')
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.,title='FLAG_OWN_REALTY')
plt.title('Income Totals per Family Status for Bottom Half of Earners')Text(0.5, 1.0, 'Income Totals per Family Status for Bottom Half of Earners')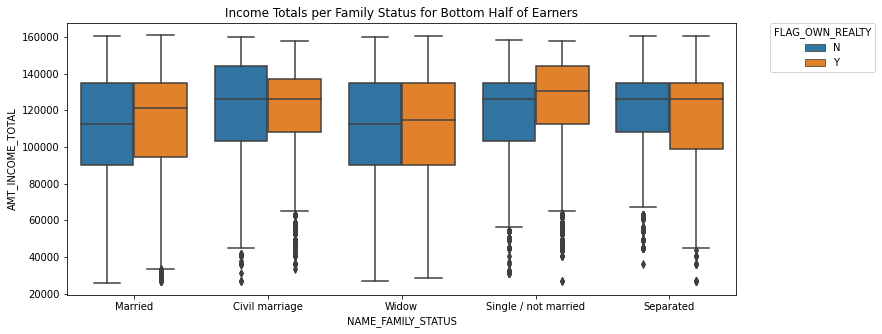
TASK: Recreate the Heat Map shown below:
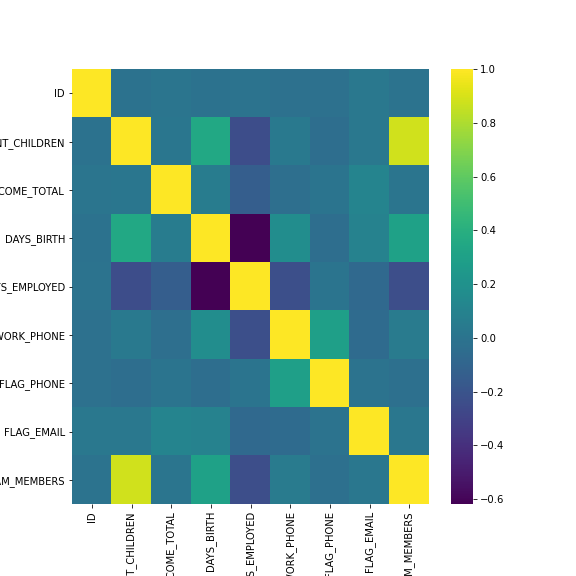
This heatmap shows the correlation between the columns in the dataframe. You can get correlation with .corr() , also note that the FLAG_MOBIL column has NaN correlation with every other column, so you should drop it before calling .corr().
df.corr()ID
CNT_CHILDREN
AMT_INCOME_TOTAL
DAYS_BIRTH
DAYS_EMPLOYEDsns.heatmap(df.drop('FLAG_MOBIL',axis=1).corr(),cmap="viridis")<AxesSubplot:>