 ++++
++++Build a basic tokenizer from scratch, implement encoder/decoder functions, and visualize how text is transformed into numerical vectors.
Make a Tokenizer 🛠️
Make a Tokenizer 🛠️
Now that we've seen the basic concepts of word-to-index mapping, it's time to put them into practice. We'll build a full tokenization pipeline for a small corpus and visualize the results.
This content is adapted from A deep understanding of AI language model mechanisms. It has been curated and organized for educational purposes on this portfolio. No copyright infringement is intended.
🚀 The Mission
Your task is to:
- Parse a multi-sentence corpus into individual words.
- Build a unique vocabulary (lexicon).
- Implement robust
encoderanddecoderfunctions. - Visualize the resulting tokens and their one-hot representations.
1. Setup & Data
We'll start with three simple sentences. Our goal is to treat them as a single corpus.
import re
import numpy as np
import matplotlib.pyplot as plt
# list of sentences
text = [ 'All that we are is the result of what we have thought',
'To be or not to be that is the question',
'Be yourself everyone else is already taken' ]
# create a vocab of unique words
allwords = re.split(r'\s',' '.join(text).lower())
vocab = sorted(set(allwords))
# create an encoder and decoder dictionaries
word2idx = { word:i for i,word in enumerate(vocab) }
idx2word = { i:word for i,word in enumerate(vocab) }
print(f"Vocabulary Size: {len(vocab)}")
print(f"Sample mapping: 'to' -> {word2idx['to']}")Vocabulary Size: 21
Sample mapping: 'to' -> 172. Encoder & Decoder Functions
Instead of manually looking up words, we need functions that can handle entire strings or lists of IDs.
### the encoder function
def encoder(text):
# parse the text into words
words = re.split(' ', text.lower())
# return the vector of indices
return [ word2idx[w] for w in words ]
### now for the decoder
def decoder(indices):
# find the words for these indices, and join into one string
return ' '.join([ idx2word[i] for i in indices ])
# Test the pipeline
newtext = 'we already are the result of what everyone else already thought'
newtext_tokenIDs = encoder(newtext)
decoded_text = decoder(newtext_tokenIDs)
print(f'Token IDs: {newtext_tokenIDs}')
print(f'Decoded: {decoded_text}')Token IDs: [18, 1, 2, 15, 12, 9, 19, 5, 4, 1, 16]
Decoded: we already are the result of what everyone else already thought3. Visualizing Tokens
Language models don't "see" text; they see sequences of integers. We can visualize this sequence to understand the density and repetition of our vocabulary.
# get all the text and all the tokens
alltext = ' '.join(text)
tokens = encoder(alltext)
# plot the tokens
_, ax = plt.subplots(1, figsize=(12, 5))
ax.plot(tokens, 'ks', markersize=12, markerfacecolor=[.7, .7, .9])
ax.set(xlabel='Word index', yticks=range(len(vocab)))
ax.grid(linestyle='--', axis='y')
# invisible axis for right-hand-side labels
ax2 = ax.twinx()
ax2.plot(tokens, alpha=0)
ax2.set(yticks=range(len(vocab)), yticklabels=vocab)
plt.show()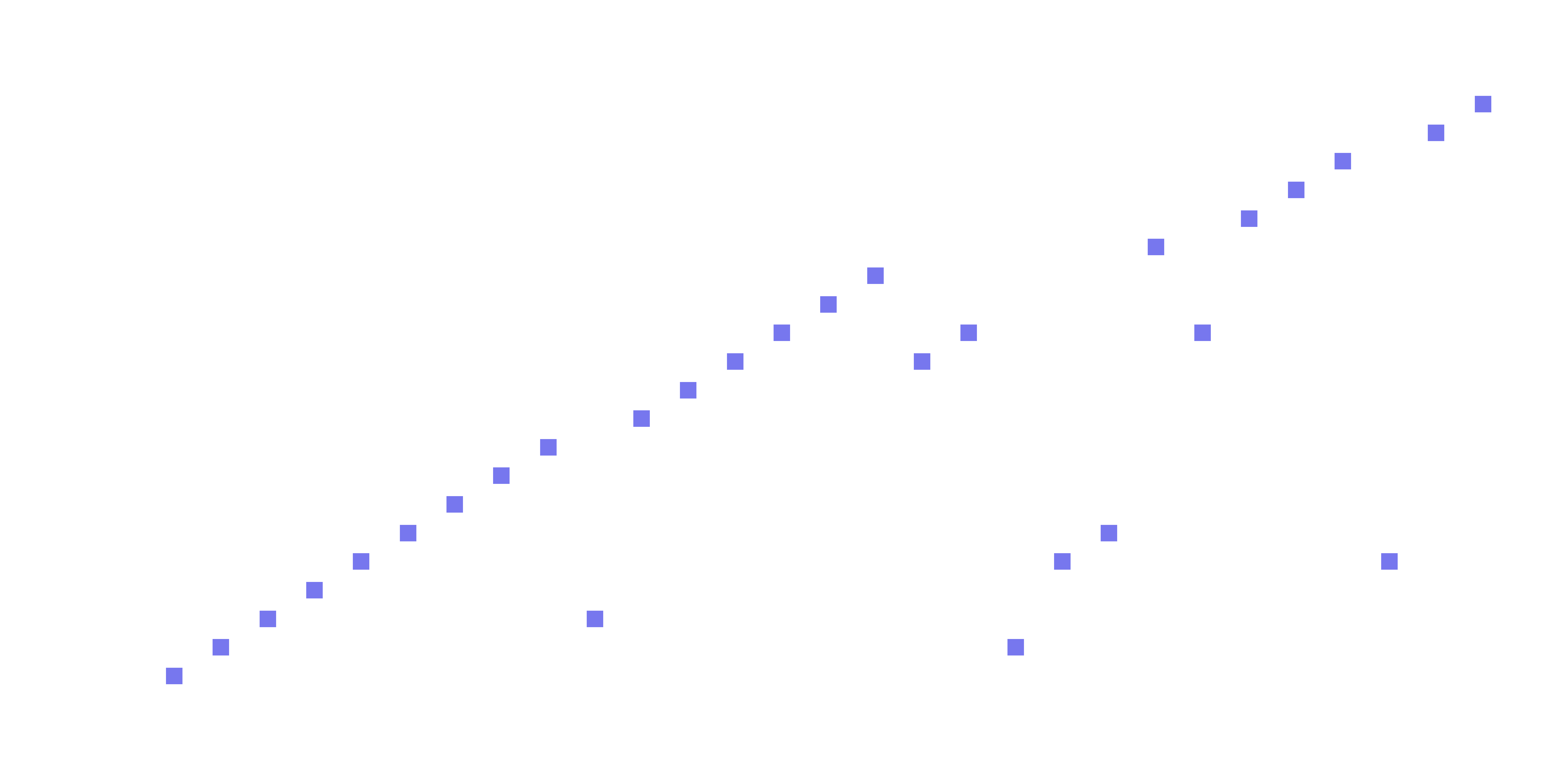
4. One-Hot Encoding 🧮
While integers are better than strings, neural networks often prefer One-Hot Encoding for categorical data. This transforms each token into a vector of zeros with a single 1 at the token's index.
word_matrix = np.zeros((len(allwords), len(vocab)), dtype=int)
# create the matrix
for i, word in enumerate(allwords):
word_matrix[i, word2idx[word]] = 1
print(f'One-hot encoding matrix size: {word_matrix.shape}')
print(word_matrix[:5, :5]) # Show a small sliceOne-hot encoding matrix size: (29, 21)
[[1 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]
[0 0 1 0 0]
[0 0 0 0 0]]💡 Key Takeaway
By the end of this challenge, we've transformed raw human language into a structured numerical matrix. This matrix is the bridge between the world of semantics and the world of linear algebra.
In the next lesson, we'll see how to prepare large-scale real-world text (like a full book) for this process!