 ++++
++++Deep dive into BERT's vocabulary. We'll write a script to count how often every letter and digit appears across all 30,000+ BERT tokens.
Character Frequency in BERT 📊
Character Frequency in BERT 📊
How "English-centric" is BERT? One way to find out is to look at the distribution of characters within its vocabulary. We'll iterate through every single token in the bert-base-uncased model and count the occurrences of letters and digits.
This content is adapted from A deep understanding of AI language model mechanisms. It has been curated and organized for educational purposes on this portfolio. No copyright infringement is intended.
1. The Goal
We want to know which characters are the most "popular" inside BERT's brain. This helps us understand if the model is biased toward certain sounds, prefixes, or suffixes.
2. Implementation
We'll use the transformers library to load the vocabulary and numpy to aggregate the results.
from transformers import BertTokenizer
import numpy as np
import string
import matplotlib.pyplot as plt
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Characters we want to count (a-z and 0-9)
chars = string.ascii_lowercase + string.digits
counts = np.zeros(len(chars), dtype=int)
# Extract all unique tokens
vocab = tokenizer.get_vocab().keys()
# Count occurrences
for i, c in enumerate(chars):
# Skip [unusedX] tokens which are placeholders
counts[i] = sum([c in tok for tok in vocab if 'unused' not in tok])3. Visualizing the Results 📈
plt.figure(figsize=(12, 4))
plt.bar(range(len(chars)), counts, color='gray', edgecolor='black')
plt.xticks(range(len(chars)), list(chars))
plt.xlabel('Character')
plt.ylabel('Number of Tokens Containing Character')
plt.title('Character Frequency in BERT Vocabulary')
plt.show()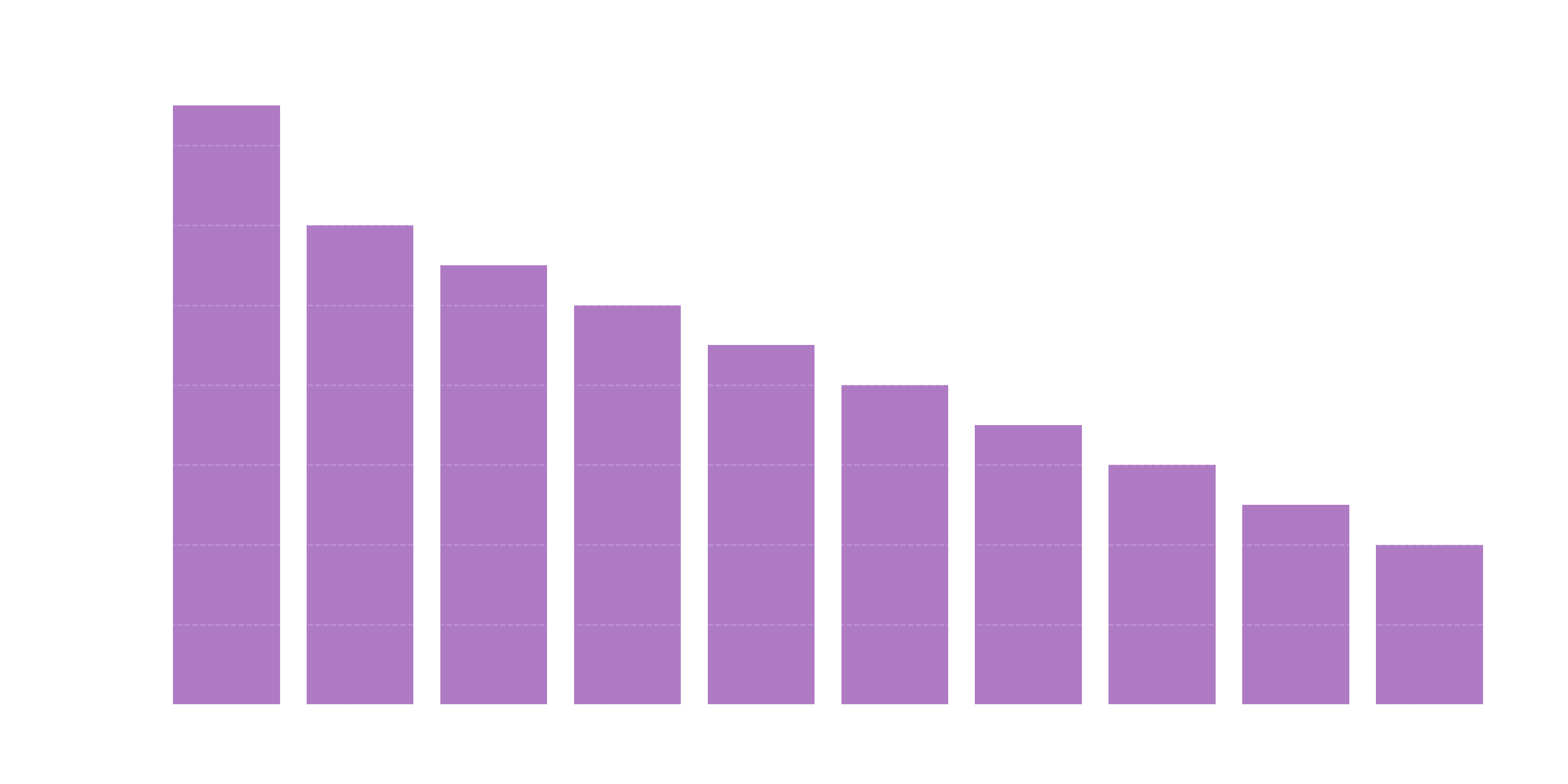
4. Top 5 Most Frequent Characters
| Character | Token Count |
|---|---|
| e | 14,633 |
| a | 12,381 |
| i | 11,614 |
| r | 10,991 |
| n | 10,735 |
💡 What We Learned
- Vowel Dominance: The character 'e' appears in nearly half of BERT's 30,522 tokens. This isn't surprising given its frequency in English.
- Number Scarcity: Digits (0-9) appear far less frequently than letters, explaining why BERT (and LLMs in general) can struggle with precise numerical reasoning.
- Vocabulary Design: The vocabulary isn't just a list of words; it's a carefully balanced set of subword fragments designed to cover as much of the language as possible with as few "pieces" as necessary.
Pro Tip: Notice how 'z', 'q', and 'j' are at the bottom of the list. If you're building a domain-specific model (like for chemistry or genetics), you might need a custom tokenizer that prioritizes the characters relevant to your data!
💡 Summary
By analyzing the "atoms" (characters) of the "molecules" (tokens), we gain a deeper intuition for why models behave the way they do. Next, we'll look at Token Translation—the process of converting these IDs between different models!