 ++++
++++Is AI more expensive for non-English speakers? We compare tokenization efficiency across Spanish, Arabic, Chinese, and more.
Tokenization Across Languages: The Fairness Gap 🌎
Tokenization Across Languages: The Fairness Gap 🌎
Most popular LLMs are trained primarily on English data. This creates a hidden disparity: the same concept might cost 1 token in English but 10 tokens in another language. This is often called the Token Tax.
This content is adapted from A deep understanding of AI language model mechanisms. It has been curated and organized for educational purposes on this portfolio. No copyright infringement is intended.
1. The Multi-Language Experiment
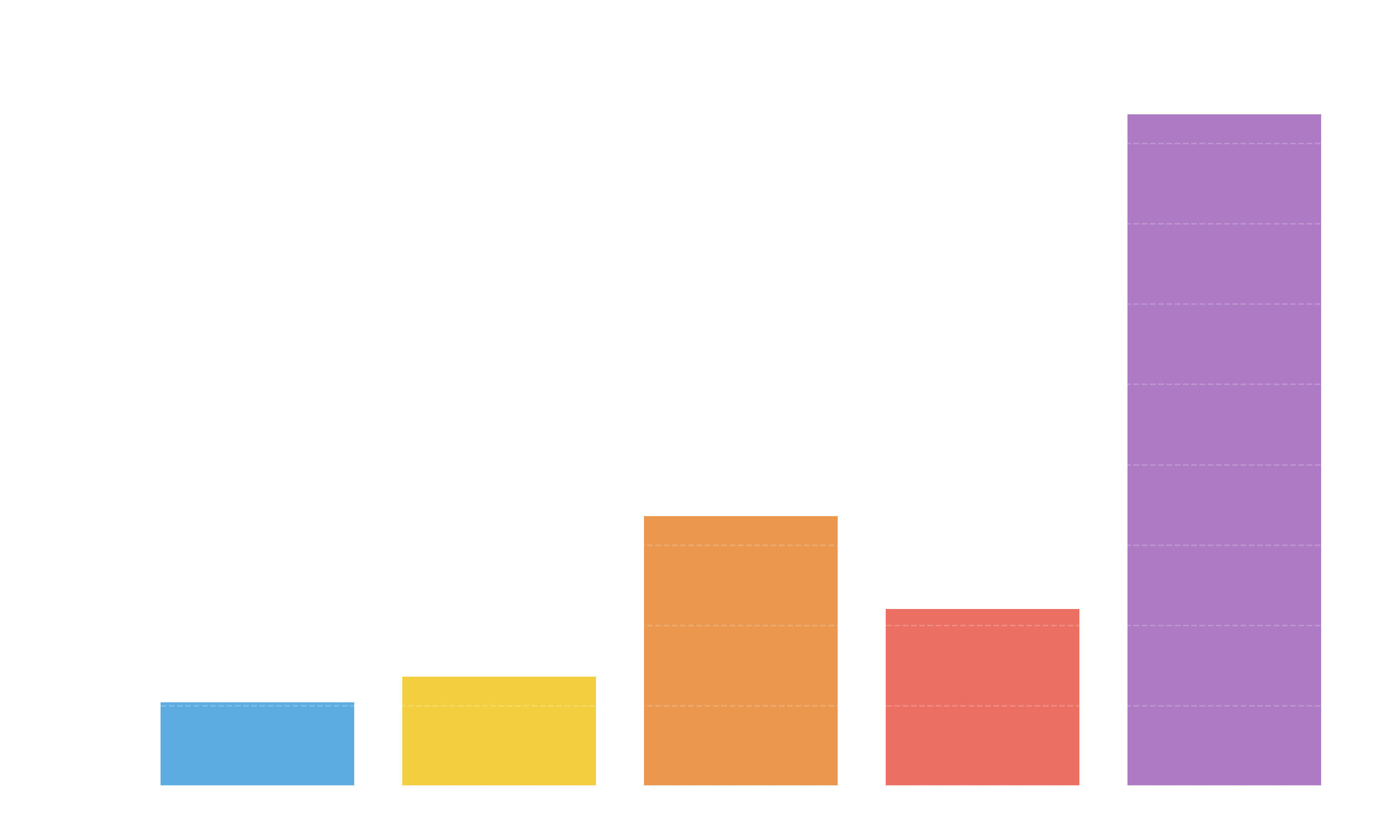
We translated the same sentence about "blue towels" into several languages and measured the token count using both BERT and GPT-4.
| Language | Chars | BERT Tokens | GPT-4 Tokens |
|---|---|---|---|
| English | 123 | 26 | 26 |
| Spanish | 132 | 46 | 34 |
| Arabic | 115 | 95 | 84 |
| Chinese | 39 | 39 | 55 |
| Tamil | 154 | 35 | 209 |
2. Key Observations 🧐
The "English Bias"
In English, GPT-4 is extremely efficient (123 chars 26 tokens). In Tamil, however, 154 characters explode into 209 tokens. This means a Tamil speaker might pay 8 times more to process the same information as an English speaker!
Roman vs. Non-Roman
Languages that use the Roman alphabet (Spanish, Esperanto) benefit from English-heavy training data because many subwords (like prefixes and suffixes) are shared. Non-Roman scripts (Arabic, Tamil) are often tokenized at the character level or even the byte level, which is far less efficient.
The Chinese Exception
Chinese is interesting. While it has more tokens than English for the same meaning, it has very few characters (39 chars 55 tokens). Because each character carries a lot of meaning, the "meaning per token" is actually quite high, even if the "tokens per character" ratio looks bad.
3. Why It Matters
- Cost: API usage is charged by token. Higher token counts = higher bills.
- Context Window: Models have a fixed token limit (e.g., 128k). If your language is inefficiently tokenized, you can fit less "story" or "data" into the model's memory.
- Performance: Models often perform slightly worse on languages where they have to think in smaller, less meaningful fragments.
Pro Tip: If you are building an app for a specific non-English market, check the tokenization efficiency of your chosen model first. Some models (like Llama-3) have significantly better multilingual vocabularies than others!
💡 Summary
Tokenization is not just a technical step—it's a socio-economic one. As LLMs become global infrastructure, the efficiency of their vocabularies across different scripts becomes a critical factor in accessibility and fairness.
Next, we'll explore a mathematical law that governs all human language: Zipf's Law!