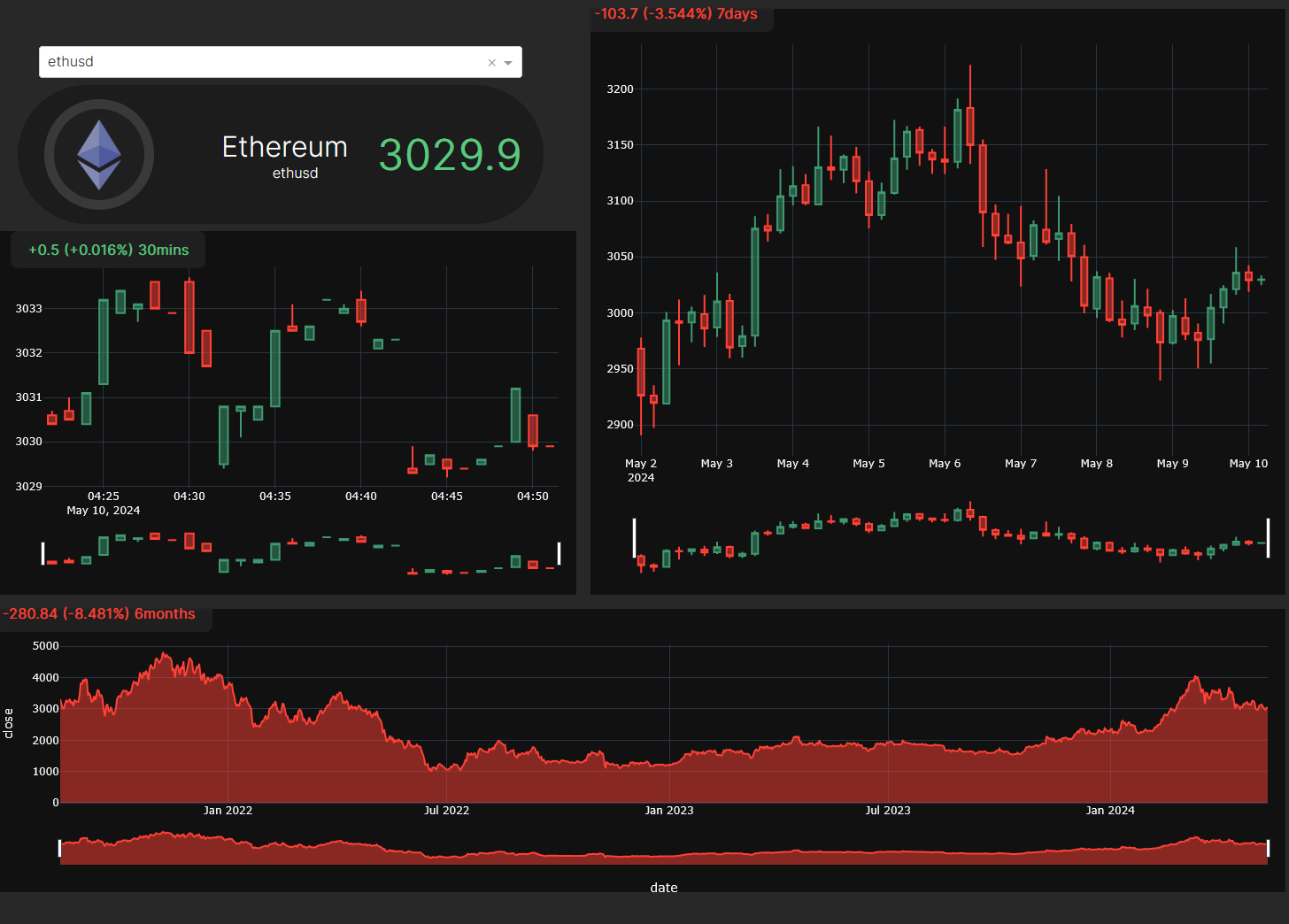
Comparison
The Comparison feature identifies discrepancies between datasets through . It uses advanced logic like and side-by-side data grids to pinpoint exact mismatches, ensuring data integrity during migrations or quality audits.
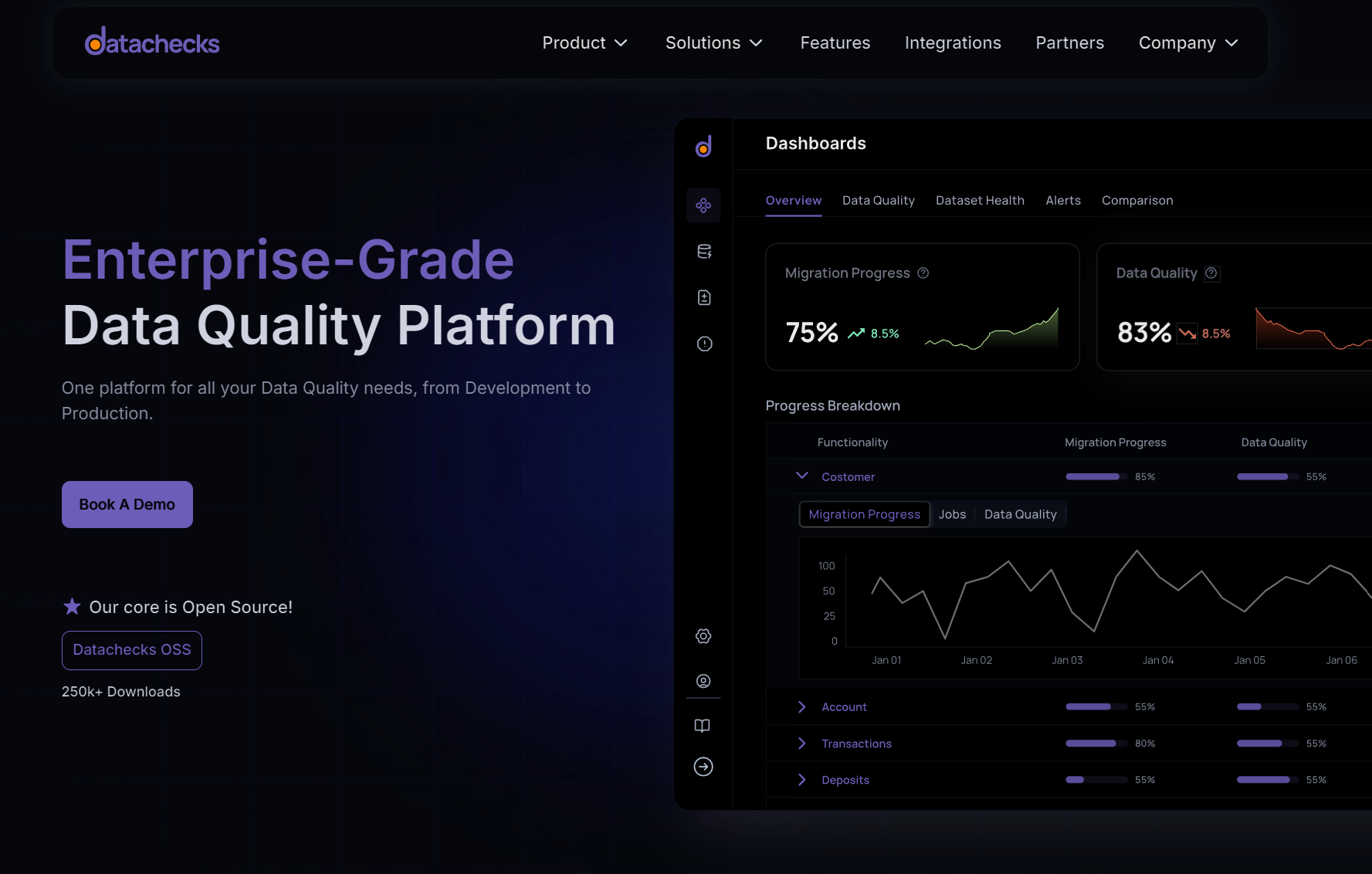
The Best Unified Platform for all your Data Quality & Observability needs, from Development to Production.
PROJECT_ID: DATACHECKS
Product view
The Comparison feature identifies discrepancies between datasets through . It uses advanced logic like and side-by-side data grids to pinpoint exact mismatches, ensuring data integrity during migrations or quality audits.
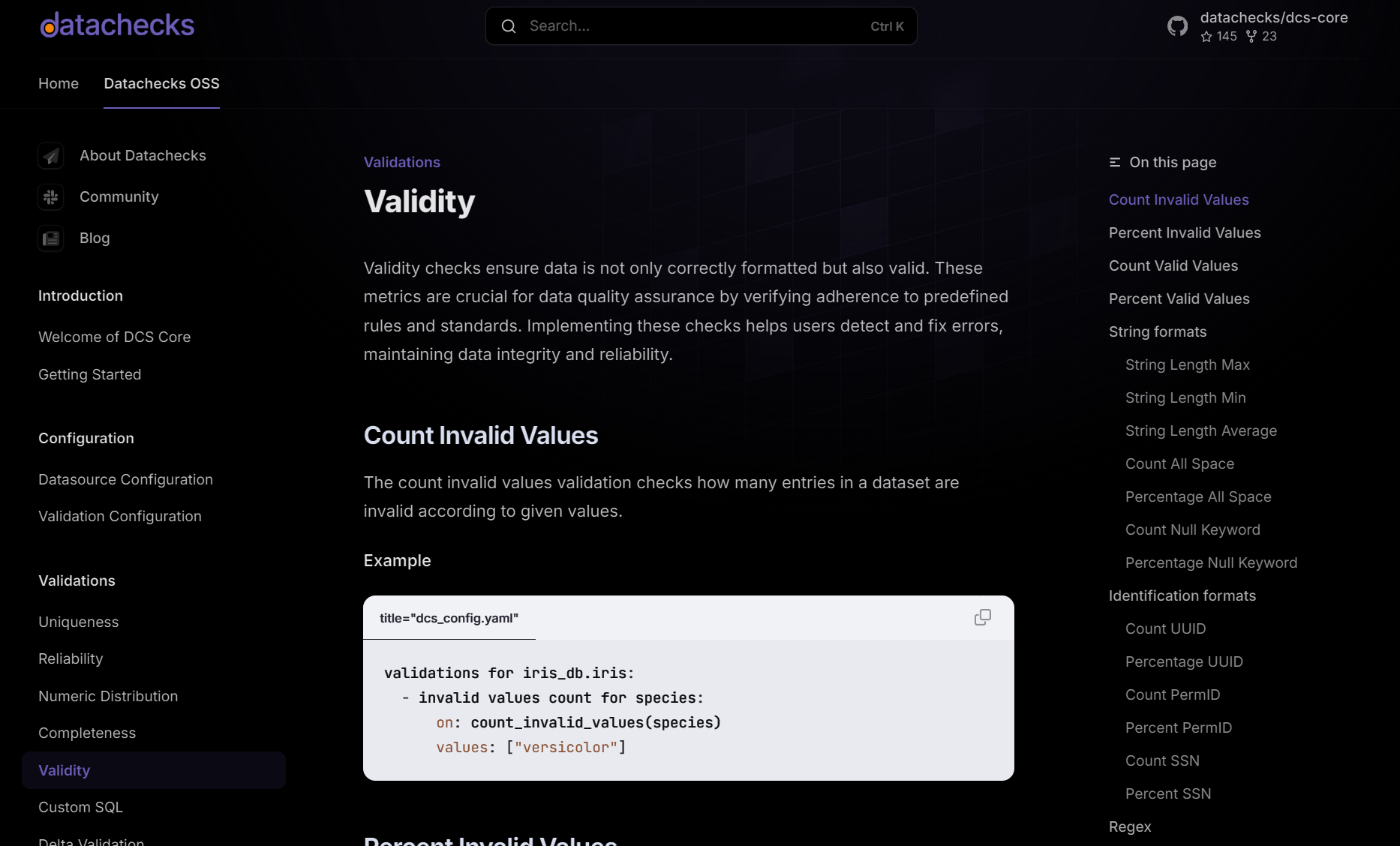
Validation features typically include (like data types, ranges, and mandatory fields) to ensure and format consistency. They also provide automated error handling, alerting users or systems to invalid entries before they can corrupt downstream processes.
Synthetic data generation creates artificial datasets that and relationships of real data without containing any original, sensitive information. Key features include to ensure realism, through PII removal, and the ability to scale or balance datasets for robust machine learning and testing.
My role
Core contributor to the Datachecks SDK, delivering across 4 repositories spanning frontend and AI agent systems.
Designed and implemented with persistent memory (Mem0), , and agent orchestration (dataset discovery, synthetic data generation).
Led a 4-member frontend team using Next.js, delivering .
to deliver core platform capabilities aligned with .
Navigate Projects
Use these cards to move to the previous or next case study.